




DATA restart 2018: Geolokácia, atribúcie, neurónové siete a ako fixnúť fuckupy
09. 04. 2018 AutorVo štvrtok sa v pražskom hoteli Olšanka reštartovali dáta! Kadiaľ sa uberajú trendy dátovej analytiky a čo ďalšie analytici prezradili?
Usporiadateľská agentúra Medio Interactive, s.r.o. vzala tento ročník pekne od podlahy. Program začal zľahka rozprávaním o tom, že vysoké školy sú všetkým možným, len nie liahňou analytikov, a pokračoval cez atribúcie a geolokácie až po využitie vnútrofiremných dát k optimalizácii cashflow. Niektoré prednášky ma vyložene zaujali, či už z hľadiska inšpirácie pre ďalšiu prácu, alebo pre svoj obsah. Ktoré to boli?
Tomáš Baxa: Za hranice Google Analytics: data-driven atribúcia s OWOX BI
Prvá z prednášok o atribučných modeloch vychádzala z predpokladu, že spravodlivý atribučný model ešte nikto nevynašiel, a to či už ide o jednoduché modely, alebo ich zložitejších príbuzných. Nástroj OWOX BI preto operuje „nad dátami“ z GA a mal by analytikom pomocou svojho atribučného modelu ukazovať zase trochu iný pohľad na výkonnosť jednotlivých kanálov.
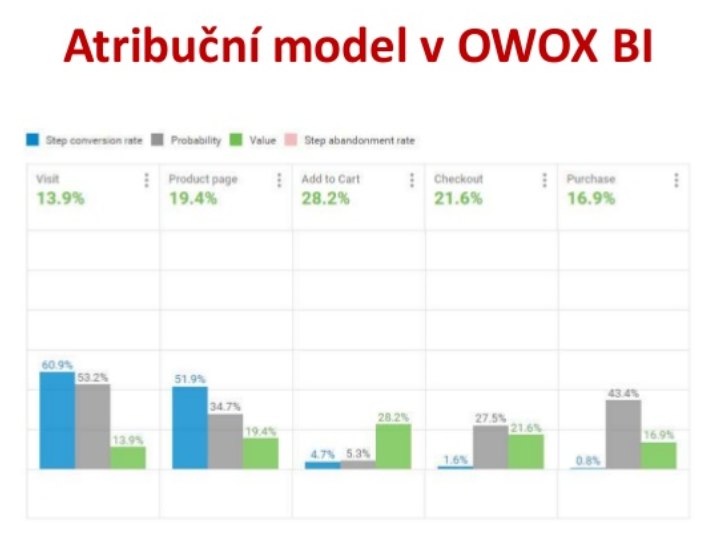
Výhodou nástroja je možnosť importovať dáta naprieč nástrojmi, nastaviť si ho tak, ako potrebujete, ovplyvniť bidding v AdWords, vytvárať reporty v Smart Data.
Prezrite si celú prezentáciu o OWOXU.
Lukáš Puchrik: Ako a prečo vyťažovať lokačné dáta v e-commerce
Ako spracovať nič nehovoriace excelovské tabuľky prostredníctvom vizualizácie do pôsobivých máp, prezradila prednáška Lukáša Puchrika. Lokačná analýza totiž umožňuje zobraziť si potrebné dáta na mape a ukázať ich v novom kontexte, ktorý by vás napríklad pri pozeraní do tisícov tabuliek a riadkov v Exceli ani nenapadol:
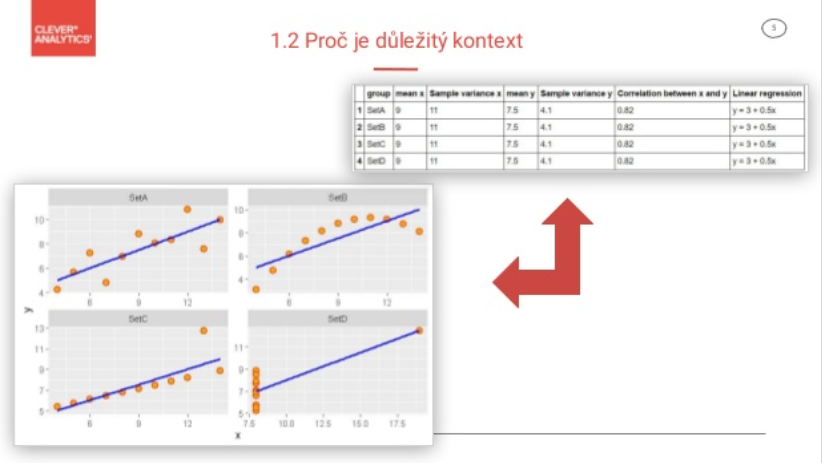
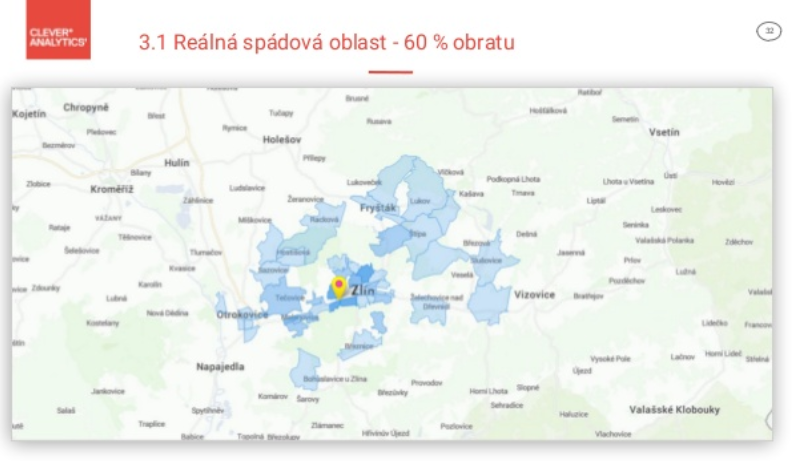
Základným predpokladom pre lokačnú analýzu sú „akékoľvek dáta, ktoré je možné lokalizovať pomocou adresy alebo rovno súradnice“. V CleverAnalytics k tomu pridajú dáta z ČSÚ a Registru územní identifikace, adres a nemovitostí, a ľahko vám tak pomôžu odhaliť napríklad reálnu spádovosť vašich zákazníkov, vhodné miesto pre vašu ďalšiu pobočku alebo analyzovať vhodnosť umiestnenia pobočiek súčasných.
Prezrite si celú prezentáciu o lokačných dátach.
Petr Bureš: Analytika vo svete startupov
Fuckupy startupov a ako sa im vyhnúť, aj tak sa táto prednáška mohla volať. Samozrejmosťou každého projektu by totiž malo byť priebežné vyhodnocovanie dát. Aby ste však mali vôbec čo vyhodnocovať, musíte dáta správne merať. Problémom môže byť meranie single page aplikácií, meranie subdomén/viac domén, registrácia alebo login zo sociálnych sietí a možno by ste to nepovedali, ale aj meranie cieľov a revenue. Peter vo svojej prednáške každú z uvedených situácií rozobral od podlahy, navrhol riešenie, upozornil na možné úskalia, a to veľmi prehľadne a zrozumiteľne. Ak máte pocit, že vás práve v týchto oblastiach tlačí topánka, prezentáciu si určite pozrite. A kto sa chce v analytike ďalej vzdelávať, mal by mrknúť aj na dve odporúčané knihy:

Prezrite si celú prezentáciu o analytike vo svete startupov.
Mirek Černý: Zvýšte vernosť zákazníkov segmentáciou
Schovávate si niekde databázu zákazníkov? Áno? A segmentuje ju? Ak áno, zaslúžite pochvalu, ak nie, najneskôr Mirkova prezentácie by vás mala presvedčiť, že sami seba oberáte o zisk. Pomocou behaviorálnej segmentácie a prioritizácie svojej databázy môžete na zákazníkov pomerne presne zacieliť. Len si s tým musíte dať tú prácu zákazníkov roztriediť do segmentov a usporiadať si ich podľa ich očakávaného prínosu v budúcnosti. Za svoj si vezmite model behaviorálnej segmentácie RFM, uvedomte si, že najväčšiu vypovedaciu schopnosť má Recency, potom Frequency a až nakoniec Monetary a zohľadnite to vo svojich KPI:
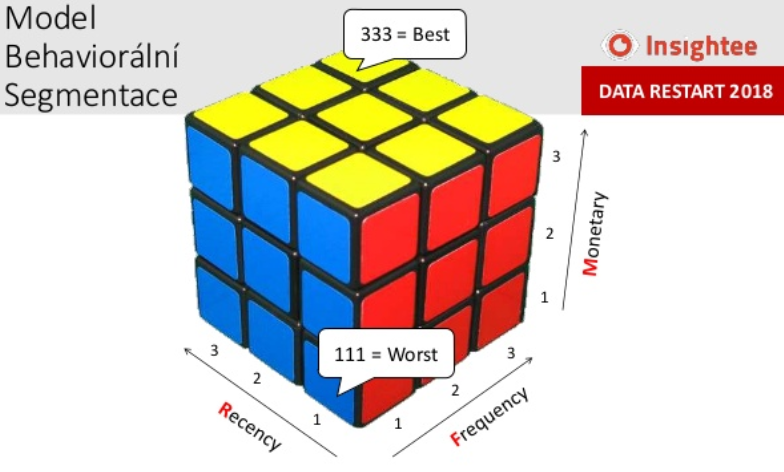
Potom si zožeňte zdrojové dáta, vytvorte si zodpovedajúce dashboardy, integrujte segmentáciu do svojho CRM a nezabudnite zapojiť aj obchodníkov. Záverom Mirkov ťahák na segmentáciu zákazníkov:

Prezrite si celú prezentáciu o segmentáciu zákazníkov.
Jan Matoušek: Hlboké učenie pre každého
Možno vám to príde rovnaké sci-fi ako mne, ale od funkčnej umelej inteligencie vás v súčasnej dobe delí 80, hoci podľa Honzu Matouška ťažkých, riadkov kódu. V praxi to znamená, že pre naprogramovanie vlastnej neurónovej siete musíte nájsť odhodlanie, vybrať si softvér, nabifľovať dokumentáciu a môžete začať veselo programovať vlastnú neurónovú sieť, ktorá vie na obrázku rozlíšiť auto od slona. Jasne, nie je to jadrová fyzika, ale nejako sa začať musí. Práve na začiatok Jan odporúča videá Stanfordskej univerzity, Datacamp a Coursera. A kompletný návod na oných 80 riadkov kódu nájdete na blogu open source softvéru Keras. Tak schválne – kto príde na budúci DATA reštart s vlastným modelom neurónovej siete?
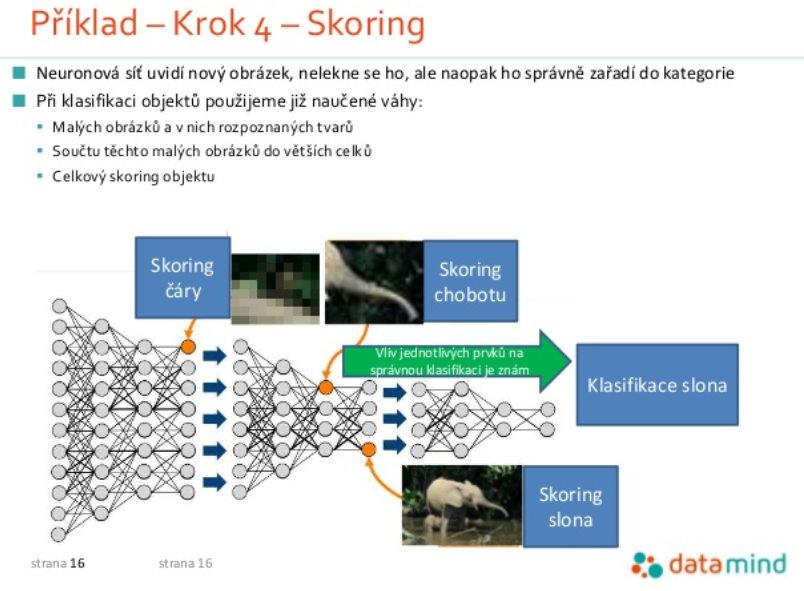
Prezrieť si celú prezentáciu o neurónových sieťach.
André Heller: Analytika vs. GDPR
„GDPR nie je o tom, či ho dodržiavate, alebo nedodržiavate, ale do akej miery ho dodržiavate.“ Nová smernica Európskej únie familiárne nazývaná džídýpíár straší po nociach markeťákov už pekných pár mesiacov. Jej hlavným problémom je istá nejednoznačnosť, ktorej sa André vo svojej prednáške venoval. Na čo všetko potrebujete od používateľov súhlas a o čom ich stačí len informovať? Akékoľvek citlivé a bežné osobné údaje (napríklad e-mailová adresa) by sa vám v analytike objavovať nemali. Podľa GDPR smiete v analytike zbierať iba IP adresy, a to ešte k tomu anonymizované, a cookies – o oboch musíte používateľa informovať. Súhlas potom potrebujete napríklad pre párovanie používateľov, remarketing alebo prepojenie s nástrojmi (áno, aj pre taký Hotjar potrebujete súhlas). Točí sa vám z GDPR hlava? Stiahnite si Andrého checklist, aby ste na niečo nezabudli, trebárs na radosť z nového internetu :):

Prezrieť si celú prezentáciu o GDPR.
Všetky prednášky nájdete na webe DATA restartu, a to vrátane ďalších zaujímavých odkazov. Tak hor sa do analytiky!




Komentáře